
《时光大爆炸》是一款时代进阶模拟经营游戏,从冰川时代开始,爆炸式进化推进时代,房子、食物、服装等等一起进行大变化,各种玩法应有尽有,采摘打猎、种田耕地、挥斧伐木、采矿炼铜,样样不能少,快来时光大爆炸一起创造属于你的文明吧!那么时光大爆炸官网...
《时光大爆炸》是一款时代进阶模拟经营游戏,从冰川时代开始,爆炸式进化推进时代,房子、食物、服装等等一起进行大变化,各种玩法应有尽有,采摘打猎、种田耕地、挥斧伐木、采矿炼铜,样样不能少,快来时光大爆炸一起创造属于你的文明吧!那么时光大爆炸官网在哪里?下面给大家带来了《时光大爆炸》官网地址入口链接分享!
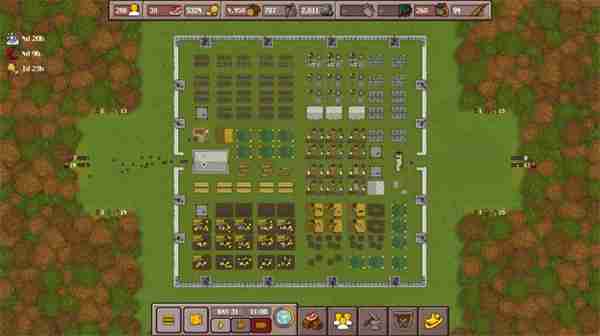
时光大爆炸官网地址入口链接:https://activity.37.com/dist/sgdbz/pc/?refer=bdpz
【时代爆炸,飙速进化】
家园发展能有多快?上一秒住小山窟,下一秒住大别墅!
冰川时代开始,爆炸式进化推进时代,房子、食物、服装等等一起进行大变化。
同时,新时代开启新玩法、新场景、新技术,每个时代都值得期待!
【轻松经营,耕田挖矿】
说到经营,采摘打猎、种田耕地、挥斧伐木、采矿炼铜,样样不能少。
我们已各就各位,就等你一声令下,立马开干!
当然,这发展可没有这么一帆风顺。或遇极端天气,或遭飞来横祸,种种考验,等待你的英明决策!
【发明科技,赚点小钱】
持续点亮科技树,发明创收新思路!
物资过剩怎么办?摆摊创业来开档!
寻觅热闹市集,售卖急求货物、成交贸易订单。
货物上架后,还需注意市场行情,抓住价格波动商机,实现繁荣度稳步提升!
以上就是《时光大爆炸》官网地址入口链接的详细内容,更多请关注知识资源分享宝库其它相关文章!
版权声明
本站内容来源于互联网搬运,
仅限用于小范围内传播学习,请在下载后24小时内删除,
如果有侵权内容、不妥之处,请第一时间联系我们删除。敬请谅解!
E-mail:dpw1001@163.com









发表评论