
Python 中的竞争条件(条件.竞争.Python...)

多线程或多进程并发访问和修改同一共享资源时,可能出现竞争条件,导致程序结果依赖于线程或进程的执行顺序。 关键点: 成因: 缺乏合适的同步机制。 后果: 产生不可预测或错误的结果,因为线程之...
Python记录:Loguru vs Logging(记录.Python.Logging.Loguru...)

python日志库对比:logging与loguru 本文将比较Python的内置logging库和流行的第三方库Loguru,帮助您选择合适的日志记录解决方案。 1. Loguru:简化日志记录...
使用 PyTM 保护应用程序:PyTM 开发人员指南(开发人员.应用程序.保护.指南.PyTM...)
利用python框架pytm高效进行威胁建模,保障应用安全 在撰写关于药品冷链系统安全论文时,我遇到了一个常见的开发难题:如何以实用且符合编码习惯的方式实现安全性。传统的威胁建模工具过于繁琐,与我的迭...
一天的天气仪表板:我如何构建一个用于API集成和云存储的Python项目(仪表板.构建一个.用于.天气.集成...)
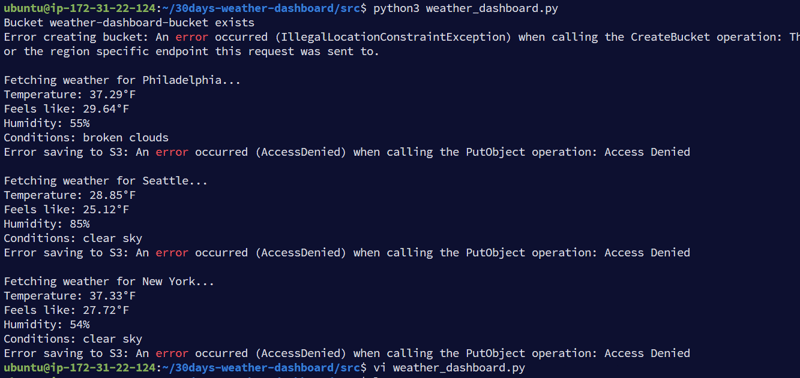
30天天气仪表盘:一个基于Python的AWS S3天气数据应用程序 本项目是一个使用python和openweather api获取多个城市天气数据,并将其存储到aws s3存储桶中的应用程序。该项...
Python虚拟环境:为什么需要它们以及如何使用它们(如何使用.虚拟.环境.Python...)

python虚拟环境(venv)详解:提升开发效率的利器 如果您从事Python开发,那么“虚拟环境”(venv)这个概念一定不会陌生。它虽然听起来有些技术性,但却能极大提升您的开发效率。本文将详细讲...
用SQLModel在Python中实现主动记录模式(主动.模式.记录.SQLModel.Python...)

Python开发者在使用SQLModel时,常常怀念Rails中优雅的数据库交互方式。本文将介绍如何在Python中,借助SQLModel实现类似Rails的Active Record模式,兼顾类型...
页面事务作为组织测试自动化的新方式(自动化.事务.页面.组织.方式...)

照片提供:mateus campos felipe 猩红鹮(Guará) 猩红鹮,学名 Eudocimus ruber,属于鹮科鸟类,栖息于热带南美洲和加勒比海地区。其外形与其他27种鹮类相似,但鲜...
在Ubuntu上安装Pytorch和Jupyterlab(安装.Ubuntu.Jupyterlab.Pytorch...)

请我喝杯咖啡☕ 第一步,更新您的Ubuntu系统: sudo apt update && sudo apt -y upgrade 确认Python版本: python3 --ver...
Day Recartory -TS + Python +重新申请和类型(类型.申请.Recartory.Day.Python...)

本文探讨了在Python中处理嵌套数据结构(字典和列表)中空字符串的通用方法。作者首先用TypeScript展示了递归处理的思路,然后逐步用Python实现,最终采用字典和列表推导式优化代码。 作者...
分布式系统:设计可扩展的Python后端(分布式.后端.扩展.设计.系统...)

现代互联网应用几乎都是分布式系统,由多台协同工作的计算机或服务器组成。这种架构能够有效应对高并发用户访问,避免单机服务器带来的性能瓶颈。例如,一个大型网站若仅依靠单服务器运行,则在用户流量激增时容易...