
一天 - 例外处理,糟糕的例子(糟糕.例外.例子...)
Python异常处理:最佳实践与常见错误 异常是程序运行过程中发生的意外事件,可能导致程序中断。Python的异常处理机制允许我们优雅地处理这些错误,防止程序崩溃。本文将探讨Python异常处理的最...
在业务中构建繁忙的REL会计软件(繁忙.构建.会计.业务.软件...)

高效的财务管理对企业和个人都至关重要。无论是追踪支出、记录交易还是生成财务报表,一个可靠的会计系统都必不可少。本文将指导您使用Python构建一个简易高效的会计软件,帮助您轻松处理基本的会计任务。...
每个数据科学家都应该知道的顶级工具(科学家.工具.数据...)

数据科学是一个多学科领域,需要运用多种工具和技术从数据中提取有价值的洞见。无论您是数据科学领域的入门者还是经验丰富的专家,掌握合适的工具都将显著提升您的工作效率。本文将为您介绍十款每个数据科学家都应...
使用Nodejs,Python,Sveltekit和Tailwindcss构建AI驱动的财务数据分析仪 - 第0部分(分析仪.财务数据.构建.驱动.Python...)
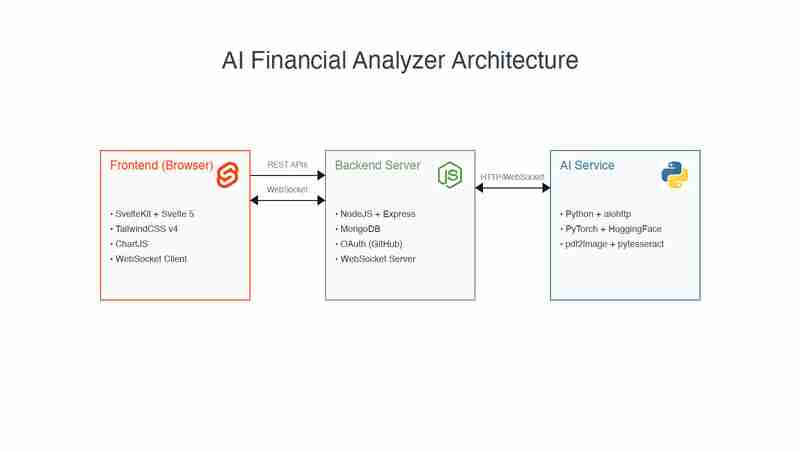
打造AI驱动的财务数据分析仪:系统架构与技术选型 在软件工程领域,紧跟技术潮流至关重要。最近,我重新学习了node.js(express.js)并着手一个新项目,目标是结合ai技术,打造一个强大的财务...
缩放数据分析:用霓虹灯,气流和简化建立起动套件(缩放.起动.气流.霓虹灯.套件...)

构建数据分析项目不再令人望而生畏!本指南提供一个轻量级、灵活且易于上手的解决方案,帮助您快速搭建一个功能强大的数据分析平台。它自动化数据收集、无服务器数据库存储以及交互式仪表板展示,所有操作都基于py...
编写Django应用程序的搜索视图(视图.应用程序.编写.Django...)

本教程演示如何利用Django框架和searchvector类构建高效的搜索视图。 为什么需要搜索? searchquery对象将用户输入的关键词转化为数据库可执行的搜索查询。默认情况下,所有关键...
掌握数据争吵:开发人员的简单指南(开发人员.争吵.简单.指南.数据...)

引言 数据争吵是将原始数据转化为可分析的、有价值信息的过程。它包含数据清洗、结构化和增强等步骤,为后续分析奠定坚实基础。 什么是数据争吵? 数据争吵,也称数据清洗或数据准备,是指将原始数据转换为结构...
为什么Python是数据科学的首选语言(首选.语言.科学.数据.Python...)

Python凭借其简洁性、多功能性和丰富的库支持,已成为数据科学领域的领先编程语言。随着数据科学持续推动各行各业的创新,Python在数据分析、机器学习和数据可视化中的作用日益重要。本文探讨了Pyt...
第二天 - 句子,订购,子查询,汇总函数,在数据库中组。(第二天.数据库中.句子.函数.汇总...)

员工信息表: empid | empname | designation | dept | salary -------+---------+----------------...
烧瓶:综合指南(烧瓶.指南.综合...)
导言 Flask是一个轻量级、模块化的Python Web框架,兼具构建强大Web应用所需的灵活性。它以简洁、可扩展性和强大的社区支持而闻名。本指南将带您从Flask的基础知识逐步深入高级特性,帮助...